Google's Firebase offers a powerful toolset for building applications. Its default database, Cloud Firestore, is a NoSQL document store.
Databases have deep-running implications on the kind of application that can be built using them. Relational databases for example work well when retrieving records by JOINing data from tables with normalized schemas. It is a terrible anti-pattern however to store the equivalent of normalized tables in Firestore and JOIN foreign keys across collections to retrieve application data. Instead, data in document databases should be denormalized and duplicated, with the application guaranteeing data integrity and preventing data anomalies.
Cloud Firestore thus lacks a convenient interface for aggregating related data at scale, and many teams find themselves in need to export Firestore collections into a relational database. Thankfully, Firebase is fully integrated into Google Cloud Platform (GCP), which offers various relational database systems to choose from.
In this post, I will use BigQuery as the data export destination, a typical choice for data analytics use cases. I will discuss two different approaches to transferring data from Firestore to BigQuery: a fully managed solution, and a custom Python script.
The Task at Hand
The goal is to transfer data from a Firestore collection named my_collection into a BigQuery table {project_id}.{bigquery_dataset}.{bigquery_table}.
The fully managed solution uses the streaming export from Firestore to BigQuery.
The more hands-on method loads data via a Python script that supports incremental updates.
Before I get going, these are the assumptions I make about my setup:
- The destination
bigquery_tablecontains historical data, but lacks data from recent days. - The entire task runs in an environment with 1 GB memory limit.
- Documents in
my_collectioninclude alast_modifiedfield, updated with the current UTC timestamp when modified. - Documents in
my_collectionaren't deleted; instead, avisibilityfield is set to"deleted".
Managed Solution: Streaming Export From Firestore To BigQuery
When requirements permit, I like using managed services on GCP. This task is no exception, with an official Firebase extension called "Stream Firestore to BigQuery" available. There's a nice blog post over at extensions.dev explaining the extension's configuration.
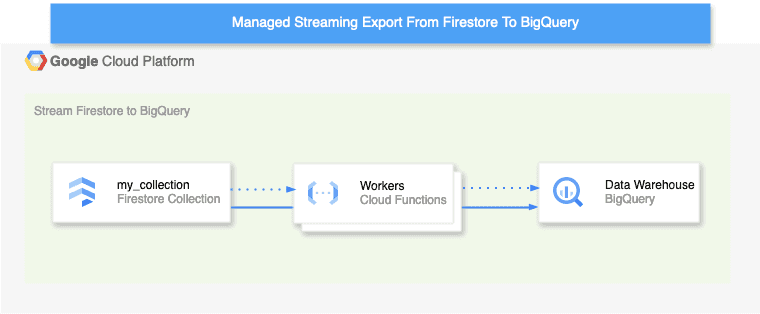
I'll omit a detailed configuration, but I want to underline that the extension is really quite powerful. Data is streamed in real-time, and the service is a safe bet in many cases. For instance, GCP Cloud Functions can act as workers to transform the streamed data before it's written to BigQuery. In the architecture drawing above, this is represented by the dotted arrows. Support for workers effectively replaces a more sophisticated streaming integration, where one would need to setup GCP Datastream or GCP DataFusion. This makes the Managed Streaming Export For Firestore To BigQuery ideal for small, greenfield projects. Also, the destination table's partitions can be configured, which helps save money and increase query processing speed for big datasets.
Fun Solution: Custom Python Code
The custom solution I propose transfers data in batches from Firestore to BigQuery. It could be deployed on GCP using a Cloud Scheduler and a Cloud Function with 1GB of memory.
The BigQuery Python SDK offers an insert_rows_json() method for adding records to a table from a list of dictionaries. We could thus fill the Cloud Functions' memory with datasets of up to 1 GB in size, and load them with insert_rows_json() in a single batch, always appending to bigquery_table. Using a timestamp last_modified and some SQL, records could be deduplicated in BigQuery afterwards.
records = [doc.to_dict() for doc in db.collection('my_collection').stream()]
client = bigquery.Client(project_id)
table_id = `{dataset_name}.{bigquery_table}`
errors = client.insert_rows_json(table_id, records) # Make an API request.
if errors == []:
print("Inserted records from Firestore")
else:
print("Encountered errors while inserting records from Firestore: {}".format(errors))For larger datasets, the above is cumbersome: The script fetches records iteratively and waits until BigQuery inserts them before fetching more, potentiallly causing long runtimes and timeouts.
There's a more robust approach however: By first storing relevant records in Google Cloud Storage (GCS) Buckets in chunks, and then leveraging BigQuery LoadJobs, extraction and loading can be decoupled.
Step 1: Retrieve the Latest Timestamp from BigQuery
Determine the most recent _inserted_at timestamp in the BigQuery table, which I call cutoff_time. Here is some simple SQL to accomplish this:
SELECT MAX(_inserted_at) AS cutoff_time
FROM `{project_id}.{bigquery_dataset}.{bigquery_table}`Step 2: Query Firestore for Relevant Documents
With the latest _inserted_at timestamp, construct a Firestore query to retrieve all documents where last_modified is greater than or equal to cutoff_time. Remember time zone complications - I'll assume last_modified timestamps are in UTC.
I decide on a chunksize of 200MB. This chunksize is arbitrary chosen, and could be further optimized, a step I omit here. I'll assume an average document size of ~0.15KB, meaning that 200 MB / 0.15 KB ≈ 1,333,333 documents into one batch, which I round to one million.
In the code below I use pagination to select batches of up to one million documents. I first order by last_modified, and iterate over all new records.
batch_size = 1_000_000
query = (db.collection('my_collection')
.order_by('last_modified')
.start_at({'last_modified': latest_timestamp}))
while True:
docs = query.limit(batch_size).stream()
docs_list = list(docs)
if not docs_list:
break
# Process the batch
last_doc = docs_list[-1]
query = query.start_after(last_doc)Step 3: Write Batches to Cloud Storage
With the documents in memory, the next step serializes it as JSON and writes it into a Google Cloud Storage Bucket:
def write_batch_to_gcs(docs_list, batch_number):
bucket_name = 'your-bucket-name'
file_name = f'data_batch_{batch_number}.json'
blob = storage_client.bucket(bucket_name).blob(file_name)
data = [doc.to_dict() for doc in docs_list]
timestamp_now = datetime.datetime.utcnow().isoformat()
data_timestamped = [{**doc.to_dict(), '_inserted_at': timestamp_now} for doc in docs_list]
blob.upload_from_string(json.dumps(data_timestamped), 'application/json')Step 4: Load Data into BigQuery
Here lies the approach's beauty: Instead of synchronously waiting for each batch to be stored in BigQuery, I create a BigQuery LoadJob for each JSON file in the GCS bucket. These jobs are executed asynchronously, allowing concurrent processing by BigQuery. The code simply polls the job's state by calling load_job.result().
def load_batch_into_bigquery(batch_number):
file_name = f'gs://{bucket_name}/data_batch_{batch_number}.json'
table_id = f'{project_id}.{bigquery_dataset}.{bigquery_table}'
job_config = bigquery.LoadJobConfig(
schema=[
bigquery.SchemaField('some_id', 'STRING'),
# your schema goes here
bigquery.SchemaField('last_modified', 'TIMESTAMP'),
bigquery.SchemaField('_inserted_at', 'TIMESTAMP'),
],
source_format=bigquery.SourceFormat.NEWLINE_DELIMITED_JSON,
write_disposition='WRITE_APPEND'
)
load_job = bigquery_client.load_table_from_uri(
file_name, table_id, job_config=job_config
)
load_job.result()Step 5: Deploy Infrastructure
In the sample infrastructure displayed below, I outline how the solution could be deployed. A Google Cloud Function loads new data into Google Cloud Storage in regular intervals using a Google Cloud Scheduler.
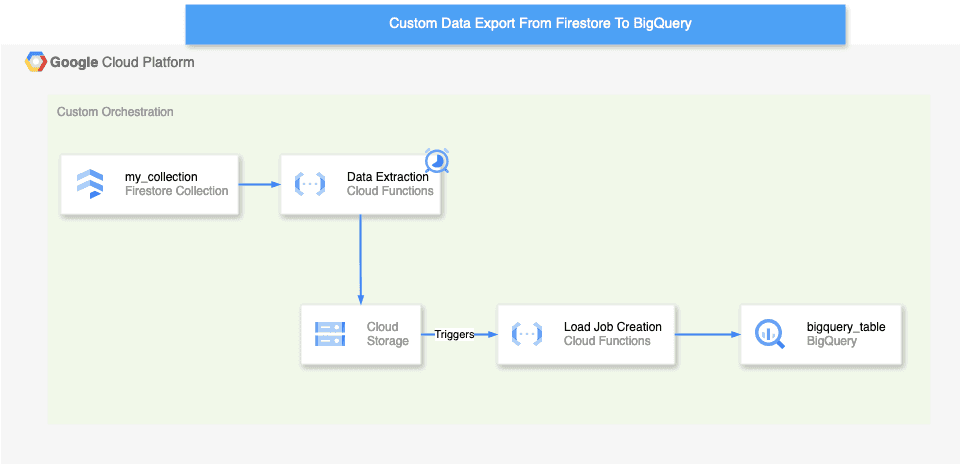
Upon creation of a new files, the storage bucket triggers yet another Cloud Function that creates one BigQuery LoadJob per file.
This Cloud Function should write logs for monitoring and error handling.
While that solution works neatly, bear in mind that maintaining multiple such extraction pipelines will become a burden over time. In cases where I find myself maintaining many ETL pipelines, I like to use Google Cloud Composer, which takes care of centralized logging, monitoring, and scheduling of all data extraction jobs.
Conclusion
In this post, I showecased the principles underlying data extraction from a document storage like Firebase into analytical databases such as BigQuery. I discussed both a fully managed solution, "Stream Firestore to BigQuery", the preferable solution if requirements permit, and a custom Python script, a more versatile solution.