Bad news first. Python is a poor choice for concurrent programming. A principal reason for this is the 'Global Interpreter Lock' or GIL. The GIL ensures that only one thread accesses Python objects at a time, effectively preventing Python from being able to distribute threads onto several CPUs by default. This leads to surprising behavior that can be tricky to navigate.
The good news is that the Python standard library makes it fairly easy to create threads and processes. In this article, I'll examine a procedure that can be used to get going with concurrent programming in Python!
A Concurrent Program in Three Steps
I recently encountered a rather elegant way to create concurrent programs. It consists of three steps. First of all, write a script that carries out the task in a sequential fashion. Secondly, transform the script so that it carries out the task using the map function. Lastly, replace map with a neat function from the concurrent.futures module.
I'll demonstrate this approach for two different problems. Firstly, I speed up a download. After that, I calculate the Fibonacci Sequence.
Scripted Image Downloader
In this example I download the first 20 images from Lorem Picsum. My scripted program looks like this:
# script_download.py
import urllib.request
import time
url = 'https://picsum.photos/id/{}/200/300'
args = [(n, url.format(n)) for n in range(20)]
start = time.time()
for pic_id, url in args:
res = urllib.request.urlopen(url)
pic = res.read()
with open(f'./{pic_id}.jpg', 'wb') as f:
f.write(pic)
print(f'Picture {pic_id} saved!')
end = time.time()
msg ='Operation took {:.3f} seconds to complete.'
print(msg.format(end-start))If I run the script, the following output is printed to the terminal:
Picture 0 saved!
Picture 1 saved!
[...]
Picture 19 saved!
Operation took 4.099 seconds to complete.Four seconds is the baseline, but let's see if I can speed up the program. Next, I formulate the problem in a functional style.
Downloading Images Using map
In the listing below, I took the part of the script that downloads and writes to a file, and wrapped it in a function called download_img.
# func_download.py
import urllib.request
import time
def download_img(pic_id, url):
res = urllib.request.urlopen(url)
pic = res.read()
with open(f'./{pic_id}.jpg', 'wb') as f:
f.write(pic)
print(f'Picture {pic_id} saved!')
def main():
url = 'https://picsum.photos/id/{}/200/300'
args = [(n, url.format(n)) for n in range(20)]
pic_ids, urls = zip(*args)
start = time.time()
for _ in map(download_img, pic_ids, urls):
pass
end = time.time()
msg = 'Operation took {:.3f} seconds to complete.'
print(msg.format(end-start))
if __name__ == '__main__':
main()In addition, I replaced the for loop with map. map originates from functional programming, and it yields an iterator that executes download_img when called. Admittedly, the pattern for _ in map() is a little odd, but bear with me - it serves as a gateway to concurrent programming.
Picture 0 saved!
Picture 1 saved!
[...]
Picture 19 saved!
Operation took 4.033 seconds to complete.Note that when running the script like this, the execution time stays the same.
Easy Concurrency
The standard library's concurrent.futures module contains a number of powerful wrappers for concurrent programming, and the official documentation is a great reference. For the sake of brevity, I've skipped to the juicy bits.
I replace
for _ in map(download_img, pic_ids, urls):
passwith
from concurrent.futures import ThreadPoolExecutor
[...]
with ThreadPoolExecutor(max_workers=20) as executor:
executor.map(download_img, pic_ids, urls)and run the resulting script.
Picture 3 saved!
Picture 0 saved!
[...]
Picture 19 saved!
Operation took 0.408 seconds to complete.A 12x speedup, just like that! Pretty impressive, right? So what is happening? The with ThreadPoolExecutor statement yields an executor. By mapping download_img and the respective argument to the executor, threads are spawned.
Once the indentation following with ThreadPoolExecutor() is resolved, all threads are terminated and the program continues to run in a sequential fashion.
From Multithreading to Multiprocessing
Introducing multiprocessing now is a cinch; I just replace ThreadPoolExecutor with ProcessPoolExecutor in the previous listing.
from concurrent.futures import ProcessPoolExecutor
[...]
with ProcessPoolExecutor(max_workers=20) as executor:
executor.map(download_img, pic_ids, urls)
[...]Picture 4 saved!
Picture 3 saved!
[...]
Picture 19 saved!
Operation took 0.451 seconds on average to complete.This is also quite fast, but why is multiprocessing slower than multithreading? As the name suggests, multiprocessing spawns processes, while multithreading spawns threads. In Python, one process can run several threads. Each process has its proper Python interpreter and its proper GIL. As a result, starting a process is a heftier and more time-consuming undertaking than starting a thread.
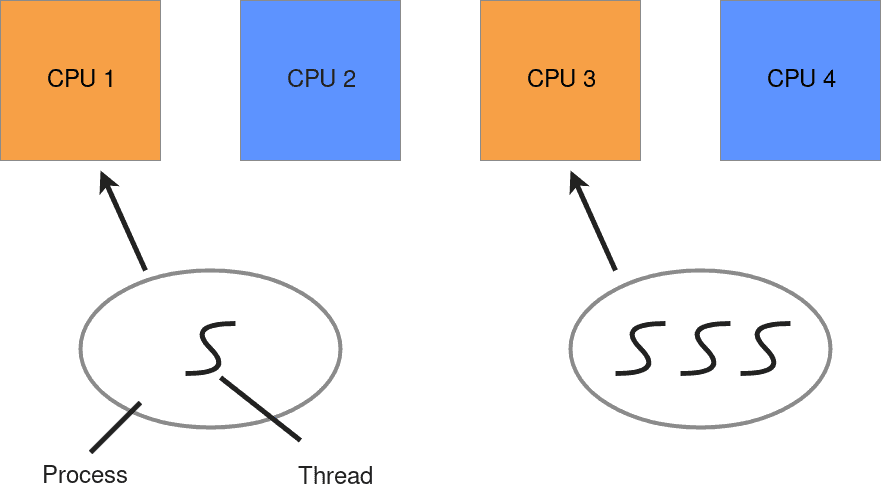
To further illustrate the difference between threads and processes in Python, I define a computationally expensive task.
def fib(n):
if n == 1:
return 0
elif n == 2:
return 1
else:
return fib(n-1) + fib(n-2)The Fibonacci Sequence is a common example of function that can be effectively described recursively. Also, computing it in plain Python without using numpy is ludicrously slow:
def main():
fib_range = list(range(1, 36))
times = []
for run in range(10):
start = time.time()
for n in fib_range:
fib(n)
end = time.time()
times.append(end-start)
print('Computing fib up to fib(35) took {:.3f} seconds on average to complete.'.format(np.mean(times)))Computing fib up to fib(35) took 5.512 seconds on average to complete.Let's speed this up with threading! To do so, I replace the for-loop with the trusted ThreadPoolExecutor like so:
with ThreadPoolExecutor() as executor:
executor.map(fib, fib_range)Computing fib up to fib(35) took 5.740 seconds on average to complete.Well, that didn't work. Although multiple threads are used, the operation takes 0.2s longer than the operation executed sequentially. Remember the GIL? I spawn a bunch of threads, but they all run within the same process and share one GIL. Even though the Fibonacci Sequence is computed in parallel, the threads merely take turns on the same CPU when computing it.
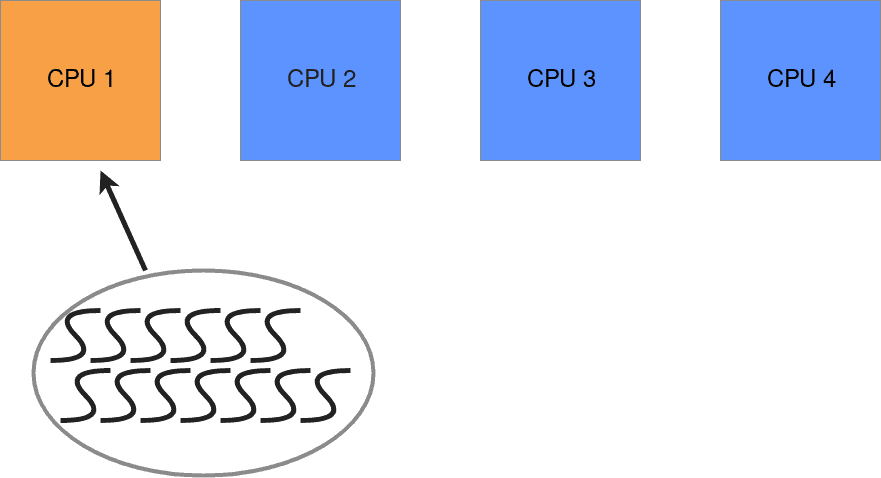
Processes can be distributed onto different cores, whereas threads running on the same process cannot. Operations that max out the CPU are called CPU-bound operations. To speed up a CPU-bound operation, multiple processes should be started. If I replace ThreadPoolExecutor with ProcessPoolExecutor, I get much better performance:
Computing fib up to fib(35) took 3.591 seconds on average to complete.Concurrency is Easy
Seeing these powerful modules in action, one might be tempted to think that concurrent computing was somewhat easy. Let me assure you that it is absolutely not. The only thing that comes easy when programming in a concurrent style is breaking stuff. It's a vast field and this article merely scratches the surface. If you want to dig deeper into concurrency in Python, there is an excellent talk titled Thinking about Concurrency by Raymond Hettinger on the subject. Make sure to also check out the slides whilst you're at it.
Further Readings
David Beazley is an absolute wizard. I highly recommend his talk Understanding the Python GIL if you want to deepen your understanding of the GIL. Furthermore, Beazley gave an incredible talk on Python Concurrency in 2015 that is worthwhile watching.
Final Thoughts
Python comes with some decent tools for concurrent programming. However, if you regularly find yourself programming in a concurrent style, chances are you're using the wrong language to get the job done. In Java, simply spawn a bunch of threads and they are automatically distributed to different cores in the background. Similarly, concurrency in Go is ridiculously easy to implement, and the language is a much better fit for high performance concurrent tasks than Python. The scripts I mention in this article are hosted on github for you to experiment with.