One of the biggest tasks to keep me busy in 2019 was research. More precisely, my work for Prof. Felix Biessmann on a new approach to Relaxed Functional Dependency (RFD) detection, and in this article I want to present and discuss that work. Research on the subject is ongoing, and as such I invite you to write me an email should you have any ideas that you'd like to share with me.
I'll assume the reader of this article has a basic understanding of the relational model, relational database theory, and functional dependency detection. In case any terms are unclear, I recommend reading the second section of my thesis or having a look at Maier 1983, chapters 1-4 and 6.
Functional Dependencies and their Relaxation
The definition of a Functional Dependency is as follows:1
Given a relation on scheme with subset and a single attribute . A FD is said to be valid in , if and only if
holds for all pairs of distinct tuples .
Using this definition, FDs can be detected on relational databases. Over the years, FDs have proven useful. Today, a relational database is normalised to 2NF in the same way it was 50 years ago: Detect FDs in the relational instance, and make sure that the only attribute in the FDs left hand side (LHS) that occurs is the relation's key.
Example
However, FDs are inflexible. Koudas et al. consider in their 2009 publication "Metric Functional Dependencies" the following scenario: A web crawler has been developed. It searches various web sources for movie titles and associated running times. Thus, it collects tuples that can be added to a relational database. For demonstration purposes, I've constructed such a dataset, and the first five rows of the resulting table are displayed below:
| Id | Duration | Source | Title |
|---|---|---|---|
| 1 | 123 | netflix.com | Pulp Fiction |
| 2 | 130 | disneyplus.com | Pulp Fiction |
| 3 | 125 | joyn.de | Pulp Fiction |
| 4 | 94 | youtube.com | The Godfather |
| 5 | 99 | hbo.com | The Godfather |
Depending on the source, the duration of a single movie differs slightly - perhaps one provider measures length differently to another.
Upon looking at the data, it is plain to see that it contains a dependency.
The movie title determines that movie's duration. However, no FD is valid, since the durations are not exactly equal, therefore a broader definition of the FD is necessary.
Metric Functional Dependency
One such RFD2 is the Metric Functional Dependency (MFD). Instead of demanding exact equality of right hand side (RHS) values, the MFD leverages a metric defined for attribute and a threshold . A MFD is said to be valid, if
In the above example, it is now possible to define the MFD with ,the Euclidean distance, and .
Index Structures as Models
In 2017, Kraska et al. published a study wherein they replaced a B-Tree with a learned model.3 This feels intuitively wrong. After all, the B-Tree is a highly optimised, battle-tested data structure used for accessing sorted records, per search.
Anyone who has ever trained a neural network or support vector machine knows that training is usually slow. In addition, trained models return values based on empirical risk minimisation (ERM) with limited precision and recall. As a result, values are returned with an error attached to them.
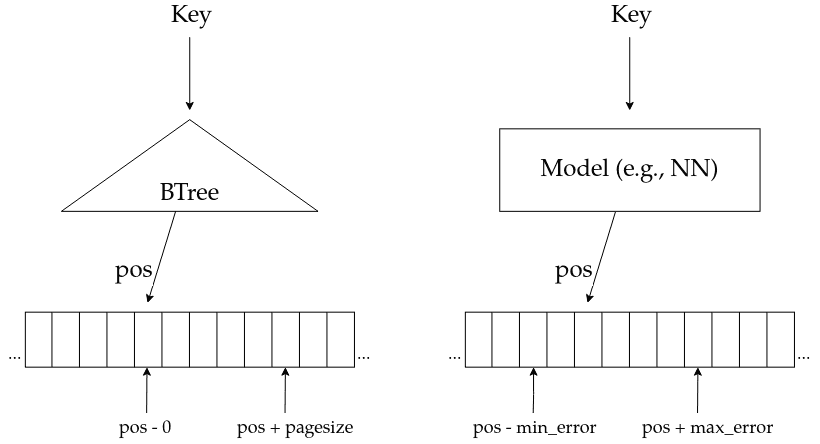
The great thing about the Kraska paper is that they accept and work within these limitations. They show that learned models can indeed be used to determine the position of a record. In addition, they argue that in some cases the learned model even out-performs a B-Tree. However, the authors make it very clear that they're not trying to prove the B-Tree should be replaced by some learned index structure. Instead, they argue that
"[...] the main contribution of this paper is to outline and evaluate the potential of a novel approach to build indexes, which complements existing work and, arguably, opens up an entirely new research direction for a decades-old field."4
Relaxations as Models
The research I did under the guidance of Prof. Biessmann tries to leverage this idea to another domain. In my thesis, I interpret the relaxation criteria, such as coverage measure, condition, approximate match or ordering criteria,5 as functions that can be approximated by a learned model.
The figure below shows a Hasse diagram. It illustrates the search-lattice a dependency detection algorithm has to operate on in order to determine minimal dependencies. In the example, the fictional relational schema is searched for non-trivial LHS combinations that functionally determine .
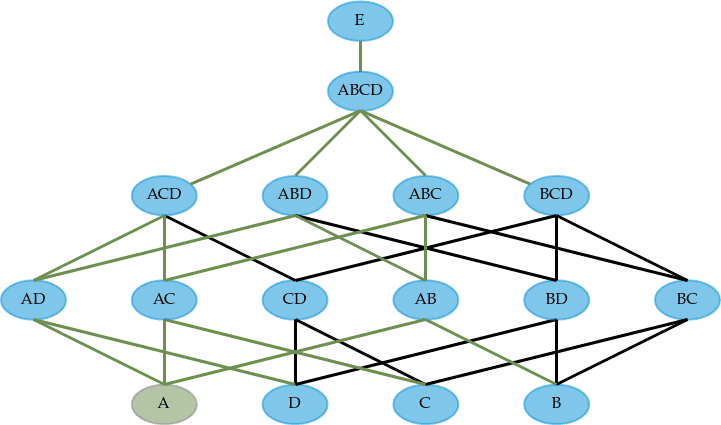
Each node in the graph is a potential LHS that might determine . Thus, when naively searching for dependencies, one can check each potential LHS to see if it determines . Normally, one would perform some kind of tuple-comparison that enforces the RFD's relaxation and checks for violations. This case is illustrated in the figure below, on the left side.
I argue that this step can be replaced by training a predictive model with data from the potential LHS. Instead of comparing tuples, the predictive capabilities of the trained model are measured on a test-set. If classifiable data is contained in the RHS's domain, performance is measured using an F1-Score, whereas a Mean Square Error (MSE) is used for continuous numerical data.
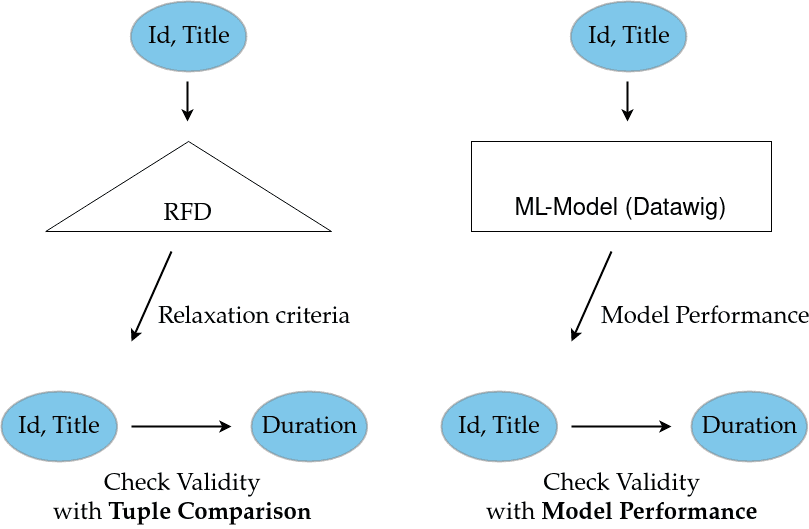
If the performance measure of one model exceeds a threshold, the corresponding LHS is considered capable of determining the RHS (see figure above, on the right). When this procedure is applied to each node in the search-lattice, it is possible to detect minimal dependencies. The animation below shows what that process might look like.

Model training is based on the DataWig framework. It has been initially develop for missing value imputation and provides powerful objects when training models. It works very conveniently with Pandas Dataframes. Furthermore, DataWig is especially powerful regarding imputation non-numerical data. It leverages clever heuristics in combination with a bunch of featurizers to transform raw data to features ready for training.
To learn relaxations, I relied on the SimpleImputer object entirely - I did not engineer any networks for specific scenarios, but used the general-purpose network provided by DataWig. I strongly encourage reading the 2018 paper by Biessmann et al for detailed information on the framework.
Capabilities of Learned Models
While working on my thesis, I developed DepDetector. DepDetector is a search algorithm that leverages learned relaxations to detect minimal dependencies. I use DepDetector to give one example where a learned model is capable of behaving like a MFD. The listing below shows an extract of the output generated when running DepDetector on the example dataset introduced in the beginning of this article.
Duration 38.4
└── [Id, Source, Title] 11.8
├── [Source, Title] 12.2
└── [Id, Title] 9.9
├── [Title] 9.9
└── [Id] 2028.5The output is a tree, and is structured in the same way as the Hasse diagram previously introduced. Each node carries an attribute name. The leftmost attribute name is the potential RHS, Duration in the extract. Next to the attribute name, a threshold is displayed. In the example . If a model has better predictive capabilities than , the attribute-combination whose domains were used in training are considered a valid LHS.
Below the potential RHS, the first potential LHS is displayed. In the extract, the potential LHS [Id, Source, Title] is valid since . Thus, all possible LHS combinations that are subsets of [Id, Source, Title] are checked next. This process continues until models for the single attributes [Id] and [Title] are trained. The model trained with data from [Title] passes the threshold, and it is therefore determined that [Title] is a minimal LHS and the RFDis valid.
Now, if you remember, is the RFD given as an example in the beginning of this article. Ergo, MFDs can be learned with DataWig models!
Final thoughts
Learned Relaxations offer a new perspective when searching for constraints in a relational database. DepDetector has been used to detect MFDs, while the program itself is still a prototype. I believe there lies great potential in the usage of trained models in dependency detection. I'm excited about future research, and I suspect hybrid approaches that alternatingly leverage conventional detection algorithms and learned models might open another interesting field of research.
You can find the code of DepDetector on github if you want to take a look at it. The entire folder in which I worked on my thesis is hosted on github, too.
- This definition is taken loosely from Abedjan et al. 2019, Data Profiling, ISBN 9781681734477↩
- For an overview of many different RFDs, I recommend reading the publication "Relaxed Functional Dependencies - A Survey of Approaches" by Caruccio et al. 2015↩
- Kraska et al. 2017, "The Case for Learned Index Structures", on arxive.org↩
- The full quote in context can be found on page 2 of the 2017 paper by Kraska et al.↩
- Caruccio et al. 2016, "Relaxed Functional Dependencies - A Survey of Approaches"↩